June 2026
Luce Spark: a 35B MoE on a 16 GB GPU, without the offload tax
A 33-35B mixture-of-experts model fires only a handful of its experts per token, but to keep it on the GPU you still pay for all of them. Luce Spark pins the experts your traffic actually uses, offloads the rest to CPU, and decodes the whole token in one fused graph so offload stops costing speed. Qwen3.6 35B-A3B runs in 13.3 GiB (down from ~20.5) and Laguna XS.2 in 14.6 GiB (down from 18.8), both on a 16 GB card that could not load them before, and decode holds ~100 tok/s, near the ~119 all-GPU ceiling. It tunes itself from live traffic. One flag, no calibration step.

TL;DR
- 33-35B MoE on a 16 GB GPU. Qwen3.6 35B-A3B: 13.3 GiB (was ~20.5). Laguna XS.2 33B-A3B: 14.6 GiB (was 18.8). Both measured on an RTX 3090, both under 16 GiB, so a 16 GB card now runs models it could not load at all.
- Only the active experts stay on the GPU. An A3B model routes to ~8 of 256 experts per token. Spark calibrates which experts your traffic hits and keeps those hot; the long tail lives in system RAM and is swapped in on demand through a bounded GPU cache.
- Self-tuning. The placement is learned from live routing and written next to the model. Each restart loads a better profile. No corpus, no offline calibration step required.
- One command, both backends.
dflash_server <model.gguf> --sparkworks for laguna and qwen35moe. The server picks the cache size, loads the learned profile if present, and keeps persisting it. - Offload without the speed cliff. Under offload, laguna runs the whole token as one fused graph, not 40 per-layer graphs. At full residency that graph is bit-identical to all-GPU and just as fast (119 tok/s); at 60% residency it holds ~100 tok/s (1.5x over a naive offload at 66). On a 16 GB card the alternative is not slower, it is "does not run".
The problem: a sparse model with a dense memory bill
Qwen3.6 35B-A3B and Laguna XS.2 are both A3B models: 35B and 33B total parameters, but only ~3B active per token. The router picks roughly 8 of 256 experts at each layer and ignores the rest. The compute bill is small. The memory bill is not: to keep the model on the GPU you hold every expert in VRAM, because any of them might be next.
On a 24 GB card that fits, barely. The experts alone are 18.2 GiB on Qwen and 16.6 GiB on Laguna; add the non-expert weights and a KV cache and you are at 18-21 GiB before context. On a 16 GB card it does not fit at all. You are paying full price for parameters that, for any given request, are mostly idle.
Standard expert offloading puts the cold experts in system RAM and computes them on the CPU. That frees VRAM but it is slow if you offload the wrong ones: pick the resident set badly and you hit the CPU tier on a third of every token's routing. The resident set is the whole game.
How Spark works
Spark is built on the hot/cold MoE offload engine that already ships in lucebox-hub. It adds the two pieces that make offload actually fast: knowing which experts to keep, and a cheap way to fix that decision while serving.
- Calibrated placement. The expert that should stay resident is the one your traffic routes to most. Spark accumulates per-(layer, expert) routing frequencies from real requests and pins the most-used set on the GPU. On held-out traffic this drops the cold-hit rate from 36% (a uniform split) to about 7%.
- A bounded expert cache, copied async. A fixed ring of spare GPU slots. When a request hits a cold expert, its weights are copied (asynchronously, from pinned host memory, overlapped with compute) into a spare slot and served on the GPU, evicting the least-recently-used entry. At 60% residency a few percent of routings still miss the resident set each token, but the copy is hidden under the matmuls instead of stalling them, so it costs throughput, not a cliff.
router picks 8 experts
hot (calibrated, pinned on GPU) ───────────► GPU
warm (in the cache ring) ───────────► GPU
cold miss ─ swap into a spare slot (LRU) ───► GPU
(rare after warmup, bounded VRAM)The cache ring is a small over-allocation of the hot expert stack, so a swap is "copy three weight tensors into a spare slot and update one routing entry". The existing GPU FFN serves it with no special path. It is the same mechanism for both backends: laguna and qwen partition hot from cold on the host, so the swap is picked up by the lookup they already do.
Memory: a 33-35B MoE under 16 GiB
Peak VRAM measured on an RTX 3090, ctx 4096. "All-GPU" holds every expert resident; "Spark" pins ~60% of expert weight and swaps the rest through the cache.
| Model | All-GPU VRAM | Spark VRAM | Saved | Fits 16 GB? |
|---|---|---|---|---|
| Laguna XS.2 (33B-A3B) | 18.8 GiB | 14.6 GiB | 4.2 GiB | yes |
| Qwen3.6 35B-A3B | ~20.5 GiB | 13.3 GiB | ~7 GiB | yes |
The footprint is set by two numbers you control: the share of experts pinned hot and the number of cache slots. Both are capped, so the total never drifts above the budget. Trade cache slots against context length to keep headroom under whatever card you are targeting.
Speed: offload, minus the tax
Offloading normally costs throughput. Two things claw it back: calibrating which experts stay resident, and decoding the token in one fused graph instead of 40 per-layer ones. Same model, same 60% residency, same 16 GB card, generating the same answer:
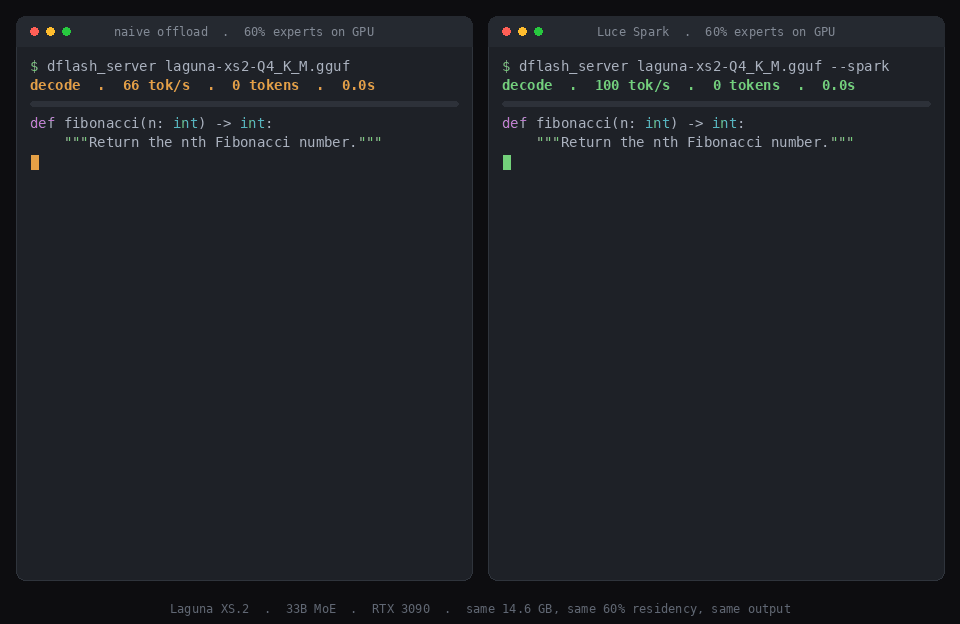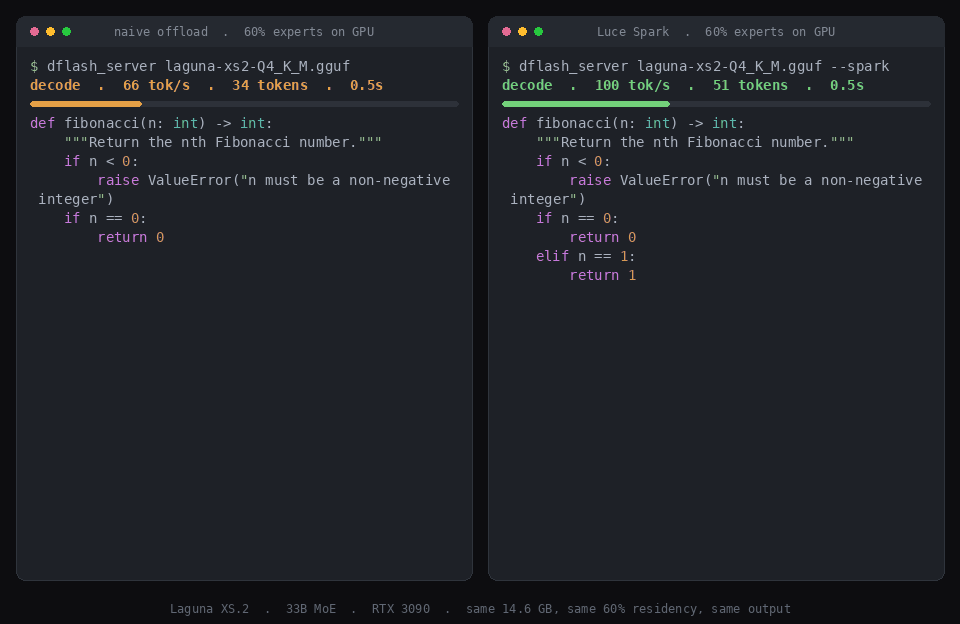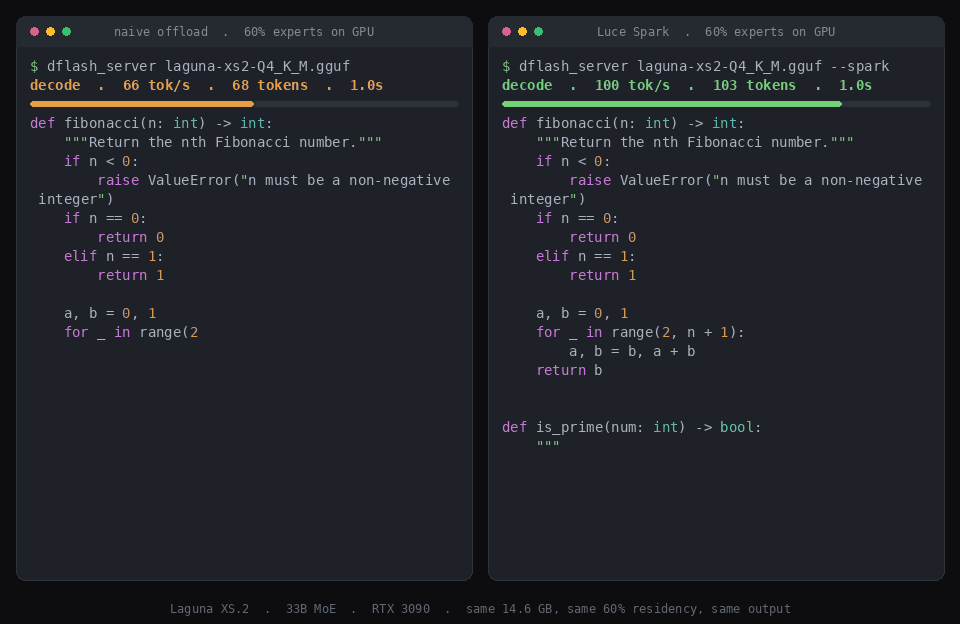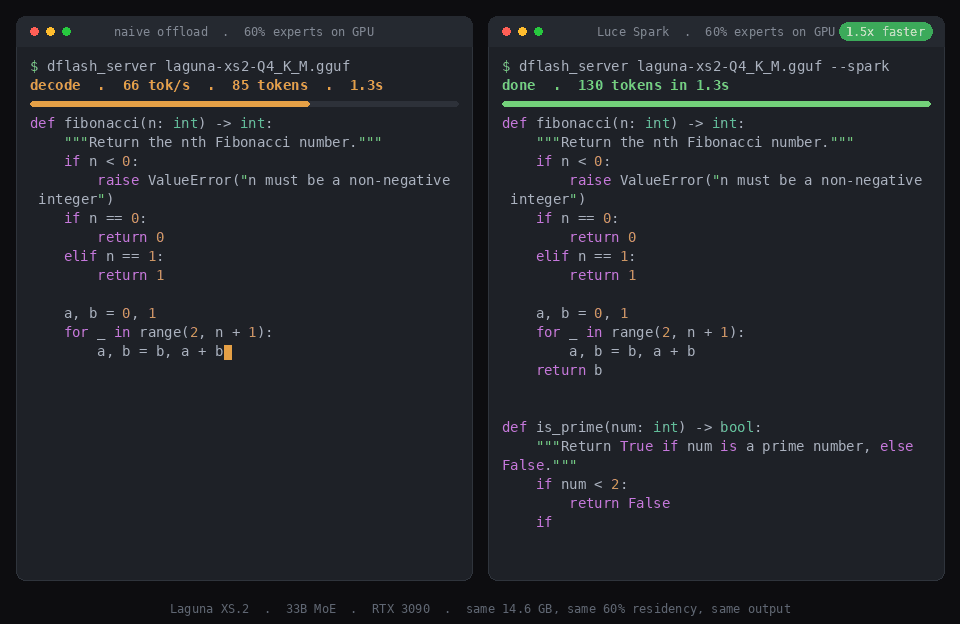
Laguna decode, 60% of expert weight resident:
| Laguna XS.2, 60% resident | Decode tok/s | % of all-GPU |
|---|---|---|
| Naive offload (uniform split) | 66 | 55% |
| Spark, calibrated placement | 81 | 68% |
| Spark, calibrated + cache + single-graph | ~100 | ~85% |
| All-GPU (needs 24 GB) | 119 | 100% |
Calibration recovers most of the gap (66 to 81). The rest was never about where the experts live, it was per-layer submission overhead: the offloaded path was building 40 separate GPU graphs per token. Folding the routed FFN into the attention graph and running the whole token as one fused graph removes that. The proof it is faithful: at full residency the fused decode is bit-identical to all-GPU (128/128 tokens, verified by spark/bench.py) and runs at the same ~119 tok/s. At 60% residency it holds ~100 tok/s, about 85% of the all-GPU ceiling and 1.5x a naive offload.
Both backends, measured. The detail above is Laguna. Qwen3.6 35B-A3B offloads even better: its expert swap hides the cold fetches without a fused graph, so it keeps 92% of all-GPU at its 13.3 GiB operating point. Each model at its Spark operating point, same RTX 3090:
| Model (Spark) | All-GPU | Spark | Speed kept |
|---|---|---|---|
| Laguna XS.2 (33B-A3B) | 119 tok/s | 100 tok/s | 85% |
| Qwen3.6 35B-A3B | 108 tok/s | 100 tok/s | 92% |
One self-tuning command
There is no pipeline to run in production. The server tunes itself from its own traffic:
# laguna or qwen35moe, same flag
dflash_server models/Qwen3.6-35B-A3B-Q4_K_M.gguf --spark
# optional: cache slots per layer (default 32)
dflash_server models/laguna-xs2-Q4_K_M.gguf --spark --spark-slots 48--spark enables the bounded cache, loads a learned placement profile from <model>.gguf.spark.csv if it exists, and keeps writing it after every request from live routing. First boot starts uniform and warms the cache within a session; each restart loads a better profile and starts warmer.
[spark] autotune ON (qwen35moe): cache_slots=16, profile=...spark.csv (loaded)
[qwen35moe] hybrid storage ready: total_hot=6053 total_cold=4187
source=hotness:.../Qwen3.6-35B-A3B-UD-Q4_K_M.gguf.spark.csvThe placement gets better the more the model serves, with no operator step. If you want a warm start on day one, the optional offline tooling in optimizations/spark/ bootstraps a profile from a corpus you provide, for example your own agent session logs, but it is not required.
Bottom line
A mixture-of-experts model is sparse in compute and, with Spark, sparse in memory too. Serving only the experts traffic actually touches puts a 33-35B MoE on a 16 GB GPU: Qwen3.6 35B-A3B in 13.3 GiB, Laguna XS.2 in 14.6 GiB, both decoding around 100 tok/s, near what the same model gets with every expert resident on a 24 GB card. It is one flag, it works for both backends, and it tunes itself the longer it runs. The class of model that used to demand a 24 GB card now runs on consumer 16 GB silicon, and on a local-inference PC that is the difference between "fits" and "does not".
Source: Luce Spark on github.com/Luce-Org/lucebox-hub (tooling and docs in optimizations/spark/, engine in server/src/common/moe_hybrid_*). Numbers measured on an RTX 3090 24 GB, Qwen3.6 35B-A3B and Laguna XS.2 at Q4_K_M, ctx 4096. Built on the merged hot/cold MoE offload engine.