April 2026
DFlash on ggml: up to 207 tok/s Qwen3.5-27B on a RTX 3090
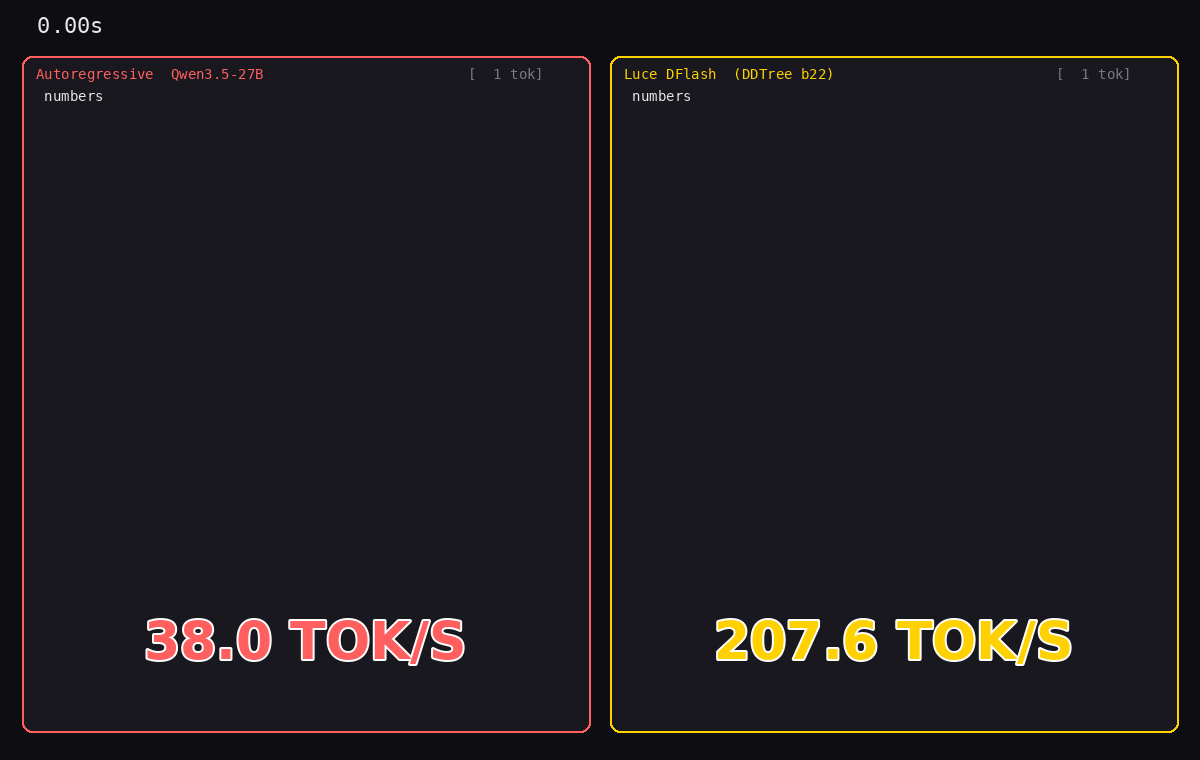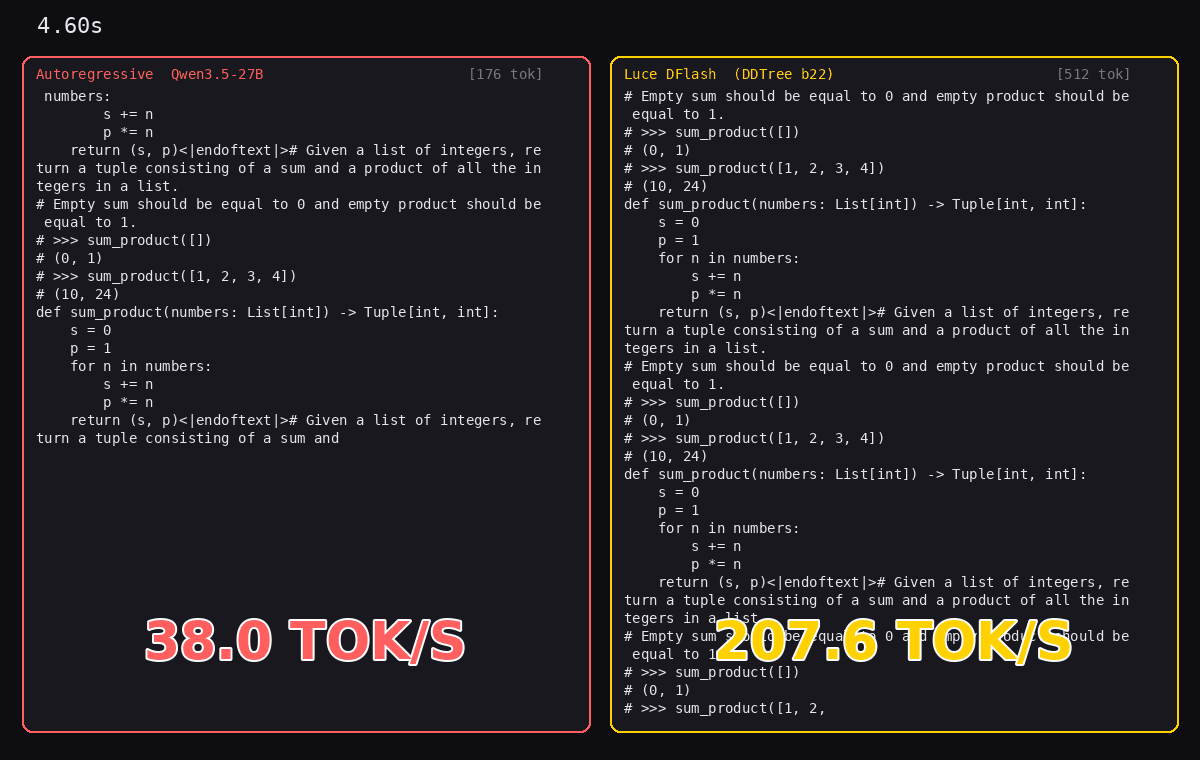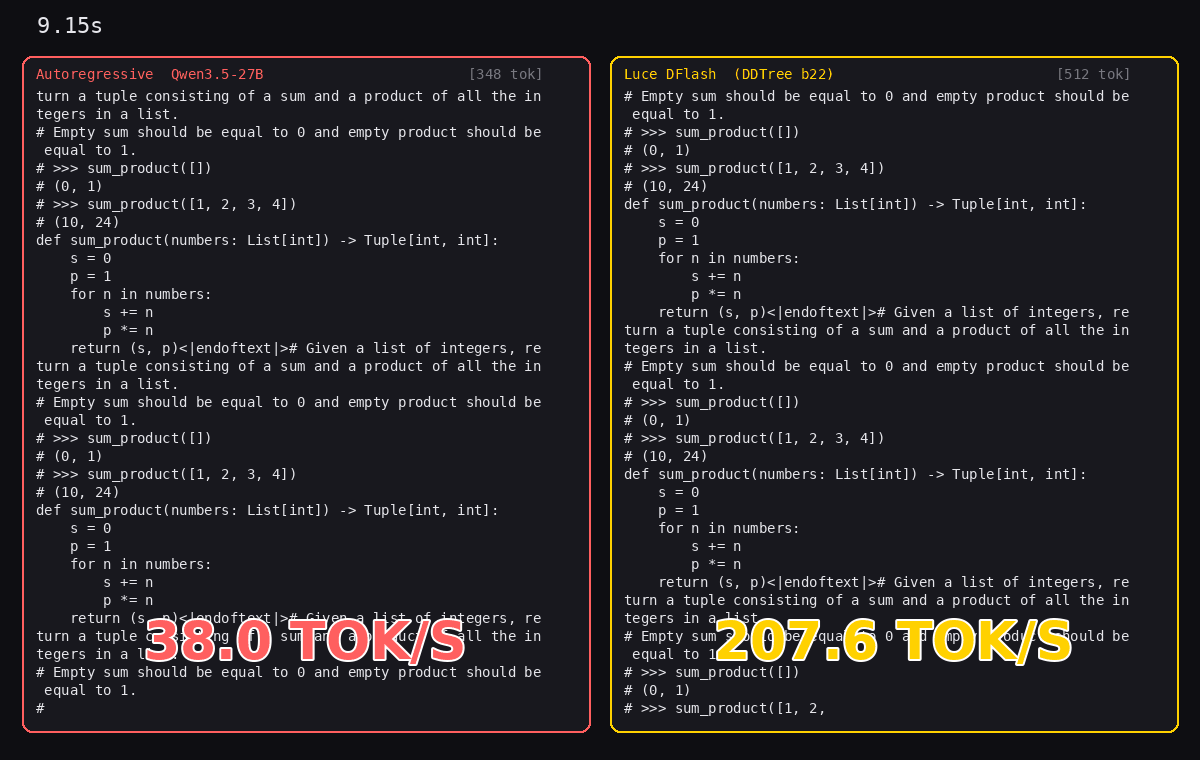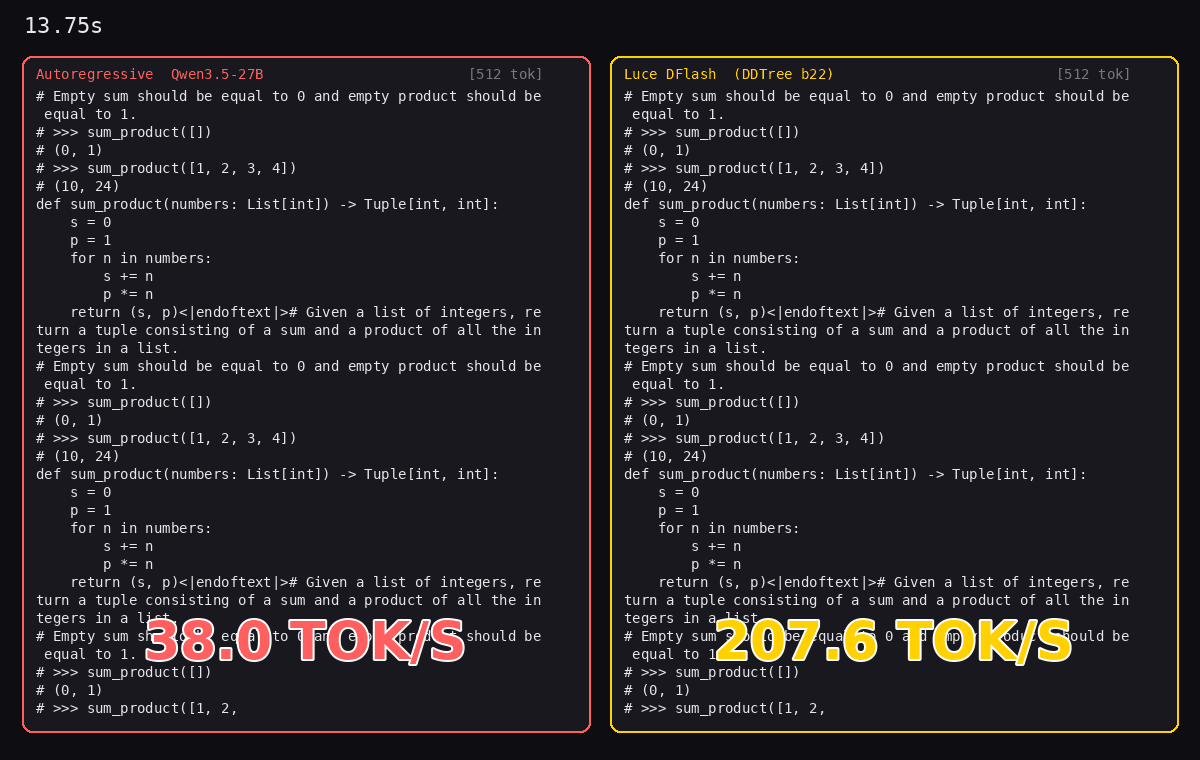
We built a standalone C++/ggml speculative decoder for Qwen3.5-27B Q4_K_M with a DFlash block-diffusion draft. The demo video shows a 207.6 tok/s run (5.46x over AR); the HumanEval 10-prompt bench averages 129.5 tok/s at DDTree budget=22, single RTX 3090, 24 GB. 3.43x over autoregressive and 2.8x over the best public SGLang AWQ number.

TL;DR
- Up to 207 tok/s in the demo video (peak 207.6 tok/s DFlash vs 38.0 tok/s AR, 5.46x). HumanEval 10-prompt bench: 129.5 tok/s mean at DDTree budget=22.
- 3.43x over autoregressive Q4_K_M baseline (37.78 tok/s).
- 2.8x vs the SGLang AWQ reference (46.6 tok/s) we tracked on the same RTX 3090.
- 128K context fits on 24 GB. Q4_0 KV cache + rolling 4096-slot target feature buffer. HE bench: 134.78 tok/s at ctx=131072.
- Only ggml. We never link libllama. Engine is ~2000 LOC of C++/CUDA built into
libdflash27b.aaroundggml_gated_delta_net.
Why the experiment exists
Qwen3.5-27B is a hybrid model: every 4th layer is full softmax attention, the rest (48 of 64) are Gated DeltaNet. M-RoPE with dimension sections [11, 11, 10, 0], 24 Q heads, 4 KV heads, key/value length 256, and an SSM state cache alongside the usual KV cache.
That combination doesn't have a good single-3090 decode path today:
- llama.cpp has the GGUF loader and
ggml_gated_delta_net, but no DFlash speculative decoding. - vLLM / SGLang both ship z-lab's DFlash integration, but only on BF16 weights (54 GB, doesn't fit on 24 GB). No GGUF path for Qwen3.5-27B on either runtime (broken on SGLang as of 2026-04). AWQ target on SGLang runs plain AR at 46.6 tok/s on one RTX 3090 but can't host a BF16 draft + DDTree tree state in 24 GB.
- z-lab's reference benchmarks run BF16 on NVIDIA B200, 54+ GB VRAM class. No public path to a 24 GB consumer card.
We wanted the fastest single-3090 decode we could get on a 24 GB consumer card, the kind of local-inference PC that runs AI models locally instead of in the cloud. The answer turned out to be: port only the graph glue to ggml, keep the DeltaNet kernel that already exists, run DFlash block-diffusion draft with a DDTree verifier, and compress the KV cache to Q4_0 for long context.
Architecture
The library is hardcoded for one model pair:
| Role | Model | Size |
|---|---|---|
| Target | Qwen3.5-27B-Q4_K_M.gguf | ~16 GB |
| Draft | z-lab/Qwen3.5-27B-DFlash | 3.46 GB bf16 |
Greedy verify, block size 16, CUDA only, single RTX 3090. The build links libggml*.a and nothing from libllama. If you deleted deps/llama.cpp/src/ it would still compile.
Layout
include/dflash27b.h Public C API
src/gguf_target_loader.cpp Q4_K_M qwen35 weights -> ggml tensors
src/safetensors_draft.cpp bf16 DFlash draft weights -> ggml tensors
src/qwen35_target_graph.cpp Hybrid forward + feature capture
src/qwen3_dflash_graph.cpp 5-layer non-causal DFlash draft graph
src/delta_net_chunked.cpp Chunked Gated DeltaNet wrapper
src/kv_cache.cpp Rolling target_hidden buffer
src/f16_convert.cu F32/F16 conversion helpers
test/test_dflash.cpp Prefill -> draft -> verify -> accept driver
test/test_vs_oracle.cpp Numerics checks vs PyTorch oracle
examples/chat.py Multi-turn CLI + OpenAI-compat server driverOracle: the PyTorch reference at megaqwen3_27b_dflash/reference/dflash_reference.py, cross-checked against the z-lab AutoModel forward at cos sim 0.999812.
From autoregressive to DDTree
Configurations on the same 10-prompt HumanEval bench, n_gen=256, RTX 3090, Q4_K_M target, bf16 draft. Rows 1–5 are the historical tuning sweep (commit f1cb9bf, AR baseline 37.44 tok/s). Row 6 is the fresh 2026-04-20 run on commit 5bb7f8c (AR baseline 37.78 tok/s). Speedup is computed against each row's contemporaneous AR:
| Mode | Mean AL | Mean tok/s | Max | Speedup |
|---|---|---|---|---|
| Autoregressive (historical, 37.44) | 1.00 | 37.44 | 45 | 1.00x |
| Chain DFlash | 7.67 | 112.82 | 150.06 | 3.01x |
| DDTree budget 20 (f32 inter) | 8.44 | 127.93 | 160.36 | 3.42x mean / 4.28x max |
| DDTree budget 22 (f32 inter) | 8.77 | 130.35 | 171.38 | 3.48x mean / 4.58x max |
| DDTree budget 20 (f16 inter) | 8.64 | 133.91 | 171.68 | 3.58x mean / 4.59x max |
| DDTree budget 22 (f16 inter, historical peak) | 8.88 | 135.8 | 159.7 | 3.63x mean / 4.26x max |
| DDTree budget 22 (fresh run, 2026-04-20) | 8.31 | 129.52 | 158.40 | 3.43x mean / 4.20x peak |
AL = average accept length (tokens accepted per verify step). DDTree paper reports +35–42% over chain DFlash on pure-attention Qwen3-4B/8B/30B-MoE (A100/B200, BF16). On our hybrid Q4_K_M/RTX 3090 combo we see +15% over chain. We think the gap comes from Q4 quantization flattening the draft softmax, which we partially patched with a chain pre-seed in build_ddtree.
Draft-accuracy ceiling. Budget sweep at 20/30/40 with f16 intermediate cache plateaus AL at ~8.9. Budget 30 gives AL 8.86 (120.49 tok/s), budget 40 gives AL 8.90 (105.10 tok/s). We are draft-ceiling bound, not verify-memory bound: a bigger tree would not help, only a better draft would.
Key wins (day-by-day log, condensed)
- f16 intermediate cache: half the memory bandwidth, +5% tok/s at the same tree budget. Bit-identical to autoregressive at 40 tokens.
- Persist-write kernel (
ggml_gated_delta_net_tree_persist): skips a 9 msggml_cpyper step, +11% across all prompts. - D2D draft
target_featcopy: removes a GPU→CPU→GPU roundtrip,cudaMemcpyAsyncsaves ~3 ms/step (+3.3%). - OpenMP top-K extract, K=32→8: -7% on the
draft_logitsstep. - Tree-aware
ggml_ssm_conv_tree: sibling nodes gather their conv window along the parent chain, not DFS order. Ports SGLang'scausal_conv1d_triton HAS_EAGLE_TREE_CUSTOM_ATTN_MASK. target_featcompaction after sibling accept: fixed stale draft features on tree branch walks, unlocked real tree rescue on 9/10 prompts.- Fast K=1 path at budget=15: skip the 11 ms CPU top-K extract when no siblings are needed.
extract_draft_topkreverse bug:sort_heap + cmp_greateralready produces descending order; an extrastd::reversewas sending the worst candidate to the tree root (accept=1 every step). One-line fix.verify_logits_bufoverflow: sizedvocab*q_lenbut DDTree readsvocab*(budget+1)past budget 15. Silent memory corruption. One-line size fix.
128K context on 24 GB
Flash-attention in ggml-cuda supports Q4_0 K+V natively, so the KV cache compression is just ggml_cpy with the built-in F32→Q4_0 quantizer on write. 8x compression over f16.
Combined with a rolling 4096-slot target_feat ring (wrap-around writes, split reads across the wrap boundary), target_feat shrinks from 6.6 GB to 0.2 GB at 128K. One binary, env-selectable:
DFLASH27B_KV_Q4=1
max_ctx = 131072
DRAFT_CTX_MAX = 2048
DFLASH27B_PREFILL_UBATCH = 16
--ddtree-budget = 16| Prompt length | Prefill | Decode |
|---|---|---|
| HE 10-prompt (ctx=131072) | n/a | 134.78 tok/s (AL 8.33) |
| 13K tokens, n_gen=64 | 42 s | 99 tok/s |
| 32K tokens, n_gen=64 | 106 s | 35 tok/s |
Tradeoffs: Q4_0 KV costs ~3% quality on HE (AL 8.56 -> 8.33) at short context and is dramatically better at long context. It is the only thing that lets 128K allocate at all on 24 GB.
Prefill
- Short prompts (≤2048 tok):
PREFILL_UBATCH=16. Matches DFlash block size and chain-verifyq_len, minimizes FA tile drift. - Long prompts (>2048 tok): auto-bump to
PREFILL_UBATCH=192. 13K prefill: 40.9 s -> 15.07 s (2.7x, ~913 tok/s). Larger batches OOM the embedded intermediate-state region insideggml_gated_delta_net. - Override via
DFLASH27B_PREFILL_UBATCH=N. - Full llama.cpp-parity prefill (~1500 tok/s) still needs a
no_interop variant that skips the embedded dst region, unblockingUBATCH > 192.
What comes next
- Daemon mode: keep the model resident across turns, first-token latency 10 s → ms. Chat REPL + OpenAI server both respawn
test_dflashper request today. - Temperature / top-k sampling in the verify path. Currently greedy-only;
temperature/top_pon the OpenAI server are accepted and ignored. - Q5_K_M / Q6_K target support. Q4_K_M costs ~30 points of per-position accept vs the paper's BF16; higher-quality GGUF quants should recover most of it, if they fit.
- Full llama.cpp integration: new
qwen35arch,llama-speculative-dflash.cpp,llama-cli/llama-serverwiring. no_interop variant to unblock larger prefill ubatches (current ceiling:UBATCH=192; full llama.cpp-parity prefill ~1500 tok/s).- Metal/Vulkan backends: not planned. Single-binary CUDA only. Anyone who wants Metal can fork.
Source: github.com/Luce-Org/lucebox-hub (open source, MIT). Cross-validated against the PyTorch oracle at cos sim 0.999812. Numbers above are from test_dflash on HumanEval 10-prompt bench, RTX 3090 Ampere sm_86, Q4_K_M target, bf16 draft, greedy verify.
Related
- Luce Megakernel: single-dispatch CUDA kernel on RTX 3090, 413 tok/s at 220W on a small hybrid DeltaNet/Attention model.
- Mac + NVIDIA eGPU myth: why llama.cpp on Metal or MLX still beats an eGPU dock on a Mac today.
- Upstream references: ggml-org/llama.cpp, sgl-project/sglang, z-lab/Qwen3.5-27B-DFlash, Qwen/Qwen3.5-27B.